Arquitetura Kubernetes

Para quem está iniciando, e muitas vezes até para quem já tem um certo conhecimento, entender a arquitetura do Kubernetes pode não ser uma tarefa muito fácil. Mas acredite, não tem nada de tão complicado assim. Um bom fundamento da arquitetura vai te ajudar a entender melhor como o Kubernetes funciona e como ele pode ser seu aliado.
Neste segundo post da minha série Kubernetes - The Hard Way tentarei explicar e exemplificar os conceitos do Kubernetes começando pela base, vamos ver infraestruturas, containers e alguns modelos de como as aplicações são executas nos dias de hoje.
E para finalizar vamos entender o porquê o Kubernetes é tão útil, quais são as arquiteturas de um cluster Kubernetes e seus principais componentes.
Se você perdeu o primeiro post desta série, não deixe de conferir. Aqui você vai aprender como instalar um cluster multi-node Kubernetes do zero que também pode ser utilizado como Lab no decorrer desta série.
Virtual Machines, Containers e Aplicações
Kubernetes certamente é o tema central aqui, mas não posso começar a falar de Kubernetes sem introduzir o que sustenta o Kubernetes.
Para ter um entendimento claro da arquitetura do Kubernetes vamos dar uma olhada geral nas infraestruturas mais comuns para execução de aplicações. Para começar vamos iniciar pelo modelo mais tradicional.
Como estamos acostumados

Este é o modelo mais tradicional, simples e como todos nós já estamos acostumados. Aqui as aplicações são instaladas no próprio host (que pode ser o seu PC ou um servidor físico), o sistema operacional e as aplicações de usuário são executadas no próprio host ou podem ser acessadas por rede.
O grande problema deste modelo é o custo e manutenção.
Como você mesmo pode imaginar, quando o seu PC não tem mais o desempenho esperado para rodar o seu jogo favorito, você faz um upgrade no PC ou simplesmente compra um novo. Todos os seus jogos e outras aplicações estão instalados no mesmo PC, se você troca de PC você precisa instalar e configurar tudo novamente. E se o PC parar de funcionar?
Agora vamos colocar esse problema na visão de uma empresa. As empresas precisam de vários servidores físicos para garantir e manter todas as aplicações funcionando para seus clientes. Quanto mais servidores físicos maior o custo para a empresa, pois mais energia é consumida, mais pessoas são necessárias para instalar os equipamentos e aplicações, dar suporte etc.
Outro grande problema que este modelo pode trazer é o desperdício de recursos computacionais, isso porque nem sempre as aplicações consomem todo o potencial do equipamento, por exemplo, um servidor de banco de dados pode consumir durante o período de trabalho 60% da capacidade com picos de 80%. Após o período de trabalho e durante a madrugada, quando não há pessoas trabalhando, o servidor fica ocioso e o consumo cai perto de 5%. Isso quer dizer que 95% da capacidade do equipamento não está sendo utilizada, este tempo ocioso de máquina é um desperdício de dinheiro para as empresas.
Para resolver parte destes problemas a Virtualização passou a ser uma opção muito atraente e viável.
Virtualização
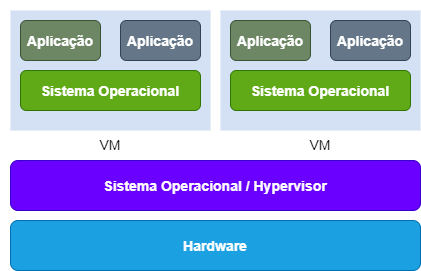
Com toda certeza a virtualização é a tecnologia mais utilizada hoje em dia, e as empresas aprenderam como aplicar a virtualização para agilizar a operação e reduzir custos.
Se comparado ao modelo tradicional anterior, ao invés de vários servidores físicos e baixo aproveitamento de capacidade, por que não aproveitar essa mesma estrutura física para suportar cargas de trabalho maiores, de forma simplificada e com menos custos. Faz todo sentido, não é?
A virtualização trouxe uma série de vantagens e a virtualização de computadores foi uma das que mais impulsionaram a escalabilidade e redução de custos para as empresas. Basta você imaginar quão fácil e rápido é colocar um novo computador virtual em operação.
Gerenciar computadores virtuais (vamos chamar simplesmente de VM a partir daqui) é muito mais fácil, rápido e barato se comparado as máquinas físicas. Toda essa simplicidade tem origem basicamente na imagem da VM que é um arquivo digital, e assim como todo arquivo as VMs podem facilmente serem padronizadas, duplicadas e compartilhadas, como um arquivo .docx do Word por exemplo.
As imagens de VM não tem dependência de máquina física (é um arquivo, lembra?) e contém tudo o que é necessário para ser iniciada, semelhante a um computador físico. Uma imagem geralmente ocupa o tamanho de gigabytes (GB) que contém os arquivos do sistema operacional, drivers e as aplicações.
Para que uma VM possa existir, ou seja, sua imagem seja executada, é necessário servidores físicos que possam compartilhar seus próprios recursos de CPU, memória, disco e rede de forma gerenciada, este tipo de servidor é conhecido como Host de Virtualização e o sistema capaz de compartilhar e gerenciar os recursos da máquina física é o Hypervisor, como por exemplo Microsoft Hyper-V, VMware, Citrix.
Embora a virtualização de VMs tenha conquistado grande importância nas operações de TI das empresas, a evolução das tecnologias e principalmente da internet, estabeleceu a agilidade como a principal característica que uma empresa deve ter para se manter competitiva. E para se manter na batalha as empresas se deram conta que a virtualização, da forma que vimos até agora, não era mais o suficiente. Então foi necessário buscar algo mais escalável, fácil e barato.
Containers

As empresas já se deram conta que ser ágil e atualizada às tecnologias é questão de sobrevivência, então, buscar soluções para desenvolver, manter e escalar aplicações de forma mais eficiente passou a ser a nova corrida do ouro. Container talvez seja a tecnologia de virtualização mais amplamente utilizada para esse fim, pois permite escalar aplicações de forma muito mais simples, segura e barato se comparado as VMs.
Containers são muito similares as VMs, basicamente tem os mesmos benefícios, porém, algumas vantagens tornam essa tecnologia mais eficiente, como por exemplo:
- Arquivos de imagem mais leves
- Menos consumo de recursos de CPU e memória
- Portabilidade entre sistemas operacionais
- Mais controle e consistência na distribuição e execução.
Assim como as imagens de VMs precisam do Hypervisor para serem executadas, containers precisam de um sistema que também seja capaz de iniciar a imagem de container e gerenciar os recursos de CPU, memória, rede e disco do container e da máquina hospedeira. Atualmente esses sistemas são conhecidos como Container Runtime Interface ou CRI e são responsáveis por acessar o Kernel do sistema operacional, alocar e gerenciar os recursos necessários para os containers. Talvez o CRI mais utilizado até o momento (e o pioneiro) seja o Docker, mas existem outras opções como o Containerd e CRI-O.
Por padrão os containers são unidades virtuais isoladas que contém apenas as aplicações, bibliotecas e arquivos de configuração. Um detalhe muito importante é que os containers não tem sistema operacional, ao contrário, fazem uso do sistema operacional da máquina hospedeira que tem o acesso gerenciado pelo CRI.
Sem a necessidade de ter um sistema operacional os arquivos de imagem de container são muito mais leves e armazenar, gerenciar e compartilhar esses arquivos faz a tecnologia de containers ter outro enorme diferencial que são os repositórios de imagens.
Basicamente existem dois tipos de repositórios, que também podem ser chamados de Registry, público (geralmente na internet) ou privado (geralmente na rede local ou internet com acesso restrito) que são responsáveis por manter as imagens de containers em local centralizado onde os usuários podem buscar e baixar uma imagem para o computador local ou inserir imagens no repositório, este processo é conhecido como pull e push respectivamente. Um exemplo de repositório público é o Docker Hub.
O processo para iniciar um container pode ser algo como o descrito:
- Usuário executa uma imagem.
- CRI verifica se a imagem do container existe no computador local, se não faz o pull da imagem (download) no repositório.
- Arquivo de imagem do container é armazenado no computador local.
- CRI executa a imagem do container.
- CRI aloca os recursos de hardware necessários e inicia o container.

Como acabamos de ver que os Containers oferecem diversas vantagens comparado as VMs e os poucos também vêm ganhando espaço, tanto que hoje em dia essas duas tecnologias de virtualização são utilizadas em conjunto, como no exemplo a seguir.

Kubernetes para que?

Espero que o que vimos até agora tenha ajudado você a ter um entendimento mais amplo das tecnologias disponíveis e do por que as empresas estão explorando cada vez mais essas tecnologias de virtualização para obter ganhos em eficiência.
A evolução não para e novos desafios sempre são postos as empresas, especialmente para as globais (ou para as que pensam expandir rapidamente) que precisam gerenciar infraestruturas complexas para executar suas aplicações.
O Kubernetes é um sistema relativamente novo (anunciado em meados de 2014 é um jovem de quase 7 anos) que foi incialmente desenvolvido pela Google como uma evolução do projeto Borg, que já era o brutamontes responsável por gerenciar milhares de containers das aplicações Google, porém, para o Kubernetes o desafio era maior; Criar uma ferramenta que lidasse com os problemas que o Borg enfrentava para facilitar o gerenciamento de milhares de containers de aplicações de escala global, tanto na execução quanto no fluxo de desenvolvimento.
Desta iniciativa nasceu o Kubernetes como projeto open source, e hoje é conhecido como uma Plataforma de Execução de Containers, ou como ele se autointitula Orquestrador de Containers.
O orquestrador de containers
Executar e gerenciar containers pode parecer uma tarefa fácil, e na verdade é quando se tem apenas algumas unidades. Mas no mundo real não é assim que funciona.
Gerenciar dezenas, centenas ou milhares de containers é uma tarefa realmente complexa, e não só por isso, as aplicações modernas necessitam de uma infraestrutura que suporte alta disponibilidade, alta capacidade de carga de trabalho, elasticidade para escalar, monitoramento, roteamento de redes e claro, algo que também abstraia parte da complexidade do gerenciamento dessa infraestrutura para os times de operações e desenvolvimento.
Essas são algumas das características que fazem do Kubernetes a ferramenta ideal, pois é uma plataforma portável e modular que por padrão fornece toda infraestrutura necessária para o gerenciamento de cargas de trabalho de containers, tais como:
- Descoberta de serviço e balanceamento de carga: O Kubernetes pode expor containers usando o nome DNS ou seu próprio endereço IP. Se o tráfego para um contêiner for alto, o Kubernetes também pode balancear a carga e distribuir o tráfego.
- Gerenciamento de storage: O Kubernetes permite que você monte automaticamente um sistema de armazenamento para containers podendo ser armazenamentos locais, em rede (ex: NFS) ou provedores de nuvem pública.
- Controle sobre rollout e rollback: Você pode descrever o estado desejado para os containers da sua aplicação e obter o controle do estado desejado em um ritmo controlado. Por exemplo, você pode automatizar o Kubernetes para criar novos containers para sua implantação, remover os contêineres existentes e controlar todos os seus recursos para o novo contêiner.
- Gerenciamento automático de recursos: O Kubernetes gerencia os nodes do cluster e controla quanta CPU e memória (RAM) cada container precisa, assim ele pode encaixar containers em nodes para distribuir carga e fazer o melhor uso de seus recursos.
- Autocorreção: O Kubernetes reinicia os containers que falham, substitui ou elimina os containers que não respondem à verificação de integridade de forma automática, além de controlar o fluxo de rede e encaminhar o tráfego para os containers saudáveis.
- Gerenciamento de configuração e de senhas: O Kubernetes permite armazenar e gerenciar informações confidenciais, como senhas, tokens OAuth e chaves SSH. Você pode implantar e atualizar dados e configuração de aplicações sem reconstruir suas imagens de contêiner e sem expor dados confidenciais em configurações.
Todas essas características fazem do Kubernetes ser de fato a plataforma "padrão" de gerenciamento de cargas de trabalho de containers. Quero dizer, "padrão" porque é de longe a mais utilizada, mas não é a única nesse mundão, Cloud Foundry e Heroku são plataformas similares que facilitam o gerenciamento de aplicações em container, assim como o Kubernetes.
Ter se estabelecido como a plataforma padrão trouxe ao Kubernetes uma enorme vantagem, todos os grandes provedores de Cloud oferecem a opção de Kubernetes gerenciado, com este tipo de serviço você não precisa se preocupar com a instalação e gerenciamento da infraestrutura, alguns serviços desse tipo são, Google Kubernetes Engine (GKE), Amazon Elastic Kubernetes Engine (EKS), Azure Kubernetes (AKS), Oracle Container Engine for Kubernetes (OKE), isso só para citar alguns.
Com diversos provedores Cloud oferecendo Kubernetes gerenciado, selecionar o melhor provedor para sustentar suas aplicações pode ser uma tarefa difícil porque envolve custos, região de disponibilidade, suporte e diversas outras questões. Mas o Kubernetes é uma plataforma e mover aplicações entre diferentes provedores Cloud é uma tarefa menos complicada caso você queria trocar de provedor.
Os benefícios do Kubernetes não se resumem apenas as Clouds, como já vimos no meu primeiro artigo Como instalar um cluster multi-node Kubernetes é possível ter o Kubernetes na infraestrutura local (on-premise), mas isso não quer dizer que você necessariamente precise gerenciar dois ou mais ambientes. Para facilitar a integração do Kubernetes on-premise com os provedores Cloud plataformas como Red Hat OpenShift e Rancher oferecem um ambiente centralizado que pode ser conectado aos provedores Cloud, essas plataformas também adicionam novos recursos como de segurança, monitoramento e ciclo de vida de aplicações que facilitam o gerenciamento, visibilidade e controle do ambiente, que agora podem ter as aplicações distribuídas entre o ambiente local e diversos provedores cloud. Esse modelo de gerenciamento transforma o seu ambiente no que hoje é conhecido como multi-clouds.
Tipos de arquitetura Kubernetes
O Kubernetes é uma plataforma projetada para fornecer uma infraestrutura em cluster com opção de alta disponibilidade dos principais componentes. Isso quer dizer que os componentes do Kubernetes podem trabalhar de forma independente e distribuídos em diferentes hosts.
Um cluster Kubernetes pode ser composto por um ou muitos hosts que são separados em dois tipos:
- Master responsável pelo gerenciamento de toda plataforma Kubernetes.
- Worker responsável por executar as aplicações de usuário.
O processo de instalação de um cluster Kubernetes varia dependendo da configuração do cluster, mas basicamente temos três tipos de instalação que são os mais comuns e que vale a pena conhecer.
Cluster Single Node

Como o próprio nome sugere, para este tipo de instalação você só precisa de um único host que assumirá as funções de Master e Worker.
Por ser o modelo mais simples, também é o menos indicado para uso em produção, sua aplicação é mais aconselhada para quem está iniciando os estudos em Kubernetes ou para desenvolvedores de aplicações que querem um ambiente mais simples para desenvolver e testar suas aplicações.
Para instalar esse tipo de cluster é possível encontrar diversas ferramentas que automatizam a instalação e que são muito úteis, a mais comum é o Minikube.
Cluster Multi Node

A configuração de clusters Multi Node requer ao menos 2 hosts, um deve ser exclusivo para a função Master e os demais para Worker.
Na prática os Workers são exclusivos para executar as aplicações de usuário e quando novos Workers são adicionados ao cluster seus recursos de CPU e memória são adicionados a capacidade total do cluster e ficam disponíveis para as aplicações, quanto mais Workers no cluster maior é o fator de disponibilidade das aplicações porque o cluster é capaz de fazer a distribuição de carga de trabalho entre todos os Workers ativos.
Para instalação desta configuração de cluster é necessário ter alguns cuidados, mas existem algumas ferramentas que auxiliam na configuração e instalação, como o Kubeadm que utilizamos em nosso Lab e que ajudam o processo.
Clusters Multi Node, como vimos, oferece a capacidade distribuição de carga e de alta disponibilidade para as aplicações, este certamente é o grande trunfo desta configuração em relação ao Single Node. Este tipo de configuração Multi Node é aconselhado para ambientes mais avançados de desenvolvimento, testes, homologação ou até mesmo para pequenos ambientes de produção que requerem alta capacidade de carga de trabalho.
Cluster de Alta Disponibilidade
Quando falamos de cluster é fácil de imaginar que a alta disponibilidade completa faça parte da solução. Mas quando falamos de Kubernetes o termo "alta disponibilidade" pode variar entre aplicações de usuário e plataforma Kubernetes.
Neste ponto acho que já está claro que a alta disponibilidade das aplicações de usuário pode ser obtida com um cluster Multi Node que pode distribuir a aplicação entre diferentes Workers. Mas, e se o Master falhar? O cluster Multi Node, incluindo todas as aplicações de usuário morrem.
Neste caso, para garantir a disponibilidade do cluster Kubernetes e das aplicações de usuário é necessário um cluster de Alta Disponibilidade, também chamados de cluster H.A (Highly Available).
Para assegurar a alta disponibilidade do cluster todos os componentes do Kubernetes devem ser distribuídos entre diferentes hosts, isso quer dizer que devemos ter mais de um Master e Worker, no mínimo três de cada para ser exato.
Você pode não ter percebido, mas acabei de introduzir os componentes do Kubernetes, que não havia mencionado até agora para não deixar as coisas mais complexas, mas neste ponto acho que posso começar a complicar as coisas porque vamos precisar diferenciar as partes do Kubernetes a partir de agora.
A configuração de um cluster Kubernetes de alta disponibilidade pode variar muito dependendo dos níveis de disponibilidade que se quer atingir, mas para iniciar, vou apresentar duas configurações de clusters mais comum, uma que tem alta disponibilidade de todos os componentes no mesmo grupo, conhecido como stacked e outra com o componente de data store, etcd, em seu próprio cluster.
Alta disponibilidade Stacked

Alta disponibilidade com Cluster etcd

A pouco eu falei que precisamos de no mínimo três hosts para o ambiente ter a capacidade de alta disponibilidade, isso quer dizer que essa configuração que acabei de apresentar garante que o ambiente se manterá disponível quando um dos hosts falhar, o que é conhecido como fator de Quórum do cluster. Para um cluster se manter alto disponível geralmente é necessário que mais da metade dos hosts estejam ativos.
De forma geral quer dizer que quanto maior o nível de disponibilidade desejado para o cluster maior será o número de hosts que devem estar ativos e proporcionalmente o custo será maior.
Componentes do Kubernetes
Agora que temos um conhecimento amplo dos tipos mais comuns de instalação de um cluster Kubernetes, vamos entrar um pouco mais fundo e conhecer os componentes do Kubernetes e começar a juntar as pecinhas para entender a arquitetura.
Control Plane
O coração do Kubernetes é o Control Plane (outro nome dado ao host com função Master) que é o responsável pelo funcionamento e controle das funções de todo o cluster.
O Control Plane é composto por alguns componentes que podem ou não ser executados em diferentes hosts, como vimos na arquitetura de alta disponibilidade. Normalmente os componentes do Kubernetes são executados como Pods, como é o caso do nosso cluster de Lab, mas esta não é uma regra pois os componentes também podem ser instalados diretamente no host como uma aplicação tradicional, este tipo de instalação é mais complexo e exigente.
Cada um dos componentes do Control Plane executam funções específicas no cluster, mas ainda assim não são os responsáveis por executar as aplicações em containers. Vamos entender um pouco mais sobre estes componentes.
API Server

O componente API Server, conhecido com kube-apiserver é o principal componente do Kubernetes, ele é o responsável por expor uma API RESTful para que todos os outros componentes possam executar operações CRUD (Create, Read, Update, Delete) no cluster, principalmente no data store, etcd.
O kube-apiserve é o único componente da infraestrutura do Kubernetes que tem comunicação direta com etcd. Isso quer dizer que todas operações nos recursos do Kubernetes devem ser feitas através de chamadas no API Server. Esta é uma característica da arquitetura do Kubernetes muito importante, pois a operações passam por validações que garantem a segurança e consistência dos dados e diminui as chances de erros e perda da integridade.
Outra característica do API Server muito importante e que precisamos saber é a observabilidade.
Observabilidade, nada mais é a capacidade que o API Server tem de informar os outros componentes do Kubernetes sobre um evento. De forma análoga, seria algo bem parecido com o porteiro do condomínio.
Como todas as operações devem passar pela API ela tem conhecimento sobre tudo o que acontece no cluster, então os componentes do Kubernetes notificam a API (o termo mais correto nesse caso é observam) sobre o interesse em receber certas informações. Voltando a analogia do porteiro, seria como se você pedisse para o porteiro te avisar no mesmo instante que algo chegar em seu nome, o porteiro recebe diversas coisas diariamente, mas assim que ele ver uma carta em seu nome ele vai te avisar sem que você precise ir até a portaria a cada 5 minutos para saber se tem algo para você.
No Kubernetes, quando um Pod precisa ser criado, as configurações deste resource são gravadas no etcd e o API Server notifica os componentes que estão observando o resource de Pod, o que gera uma cadeia de eventos no cluster, como por exemplo no componente scheduler que irá tomar as ações necessárias para encontrar um lugar para o Pod.
etcd
O componente etcd, como já mencionado, é um data store que nada mais é um banco de dados não estruturado de chaves e valores, sua principal função (como qualquer outro banco de dados) é persistir os dados dos objetos do Kubernetes, como por exemplo recursos de Pods, Deployment, Secret, ReplicaSet etc.
O etcd é outro componente essencial da infraestrutura do Kubernetes, ele não pode ser substituído por outro tipo de banco de dados, porém, ele não é um banco de dados exclusivo do Kubernetes ou proprietário, muito pelo contrário.
Assim como o Kubernetes o etcd também é um projeto open source, seu principal objetivo é oferecer um data store confiável e consistente, principalmente para clusters ou sistemas distribuídos. O etcd não tem dependência de outros sistemas para ser gerenciado e pode ter seu próprio cluster de alta disponibilidade e tolerante a falhas que conta com recursos avançados para garantir a consistência de dados.
O grande diferencial do etcd em comparação a outros sistemas de banco de dados é sua funcionalidade de observabilidade onde outras aplicações conseguem responder às alterações de dados (lembra do API Server?).
Scheduler
O componente kube-scheduler é o responsável por gerenciar os Pods no cluster. Para tentar explicar vou recorrer novamente a analogia, se voltarmos ao condomínio o Scheduler seria um agente imobiliário que é responsável por encontrar o melhor apartamento para seu cliente de acordo com suas exigências.
O scheduler observa no API Server novos recursos de Pod, verifica os requisitos e encaminha o Pod para o melhor Worker disponível no cluster.
Por padrão o Scheduler usa um método para distribuir os Pods entre todos os Workers ativos no cluster a modo de balancear a carga de trabalho, porém, uma série de fatores como recursos de hardware (CPU, memória, disco), configurações de afinidade e anti-afinidade, label etc influenciam na decisão do Scheduler.
Existem diversas maneiras de como você pode
influenciar na decisão do Scheduler e endereçar um determinado Worker ao Pod, a principal delas é com o
uso do seletor nodeSelector que assina de forma explicita no Pod o Worker desejado, mas
existem casos que você deve fazer uma seleção de critérios, como por exemplo um Worker que tenha discos
SSD e mais de 16GB de memória disponível, para casos assim é possível usar os labels.
Controller Manager
O componente kube-controller-manager é o responsável por executar os processos dos controllers da infraestrutura do Kubernetes.
Como já vimos anteriormente o componente API Server não faz nada além receber as requisições e enviar para etcd persistir os dados e depois notificar os componentes das alterações, o Scheduler apenas assina o Worker no Pod, mas o Kubernetes tem uma série de recursos que precisam existir, então temos os controllers. E só para não sair do costume vou voltar a usar a analogia do condomínio, neste contexto o Controller Manager seria a equipe de zeladoria, as pessoas que são as responsáveis por executar diversas tarefas no condomínio para manter as coisas em ordem.
Os controllers podem ser internos do Kubernetes ou externos (veremos um exemplo logo mais), alguns dos principais controllers internos são:
- Node controller
- Replication controller
- Deployment controller
- Endpoints controller
- Service controller
- PersistentVolume controller
Cada controller tem sua função bem específica e nunca se comunicam entre si, na verdade nem sabem da existência um dos outros, mas todos seguem basicamente o mesmo processo: observam o API Server e fazem alguma tarefa em resposta ao evento. Assim como no condomínio que tem a equipe de jardinagem que sempre apara a grama quando está alta ou o eletricista que substitui a lâmpada queimada.
A quantidade de controllers internos do Kubernetes é bem extensa, não cabe explicar cada uma delas aqui, mas acho que dá para pegar a ideia da função que cada uma desenvolve apenas pelo nome.
Cloud Controller Manager

O componente cloud-controller-manager tem função semelhante ao anterior, kube-controller-manger, mas como seu próprio nome indica tem um propósito diferente, ele é responsável por gerenciar os controllers que integram com os serviços de provedores Cloud, como por exemplo AWS, GCP, Azure etc.
O Cloud Controller Manager é um componente externo que não faz parte da instalação padrão de um cluster Kubernetes.
Em teoria um provedor Cloud pode desenvolver seus próprios componentes e disponibilizar para seus clientes que querem integrar o cluster Kubernetes on-premise aos serviços do provedor.
Não há uma regra sobre quais controllers um provedor deve oferecer, mas os principais são:
- Node controller
- Route controller
- Service controller
Com o Cloud Controller Manager instalado novos recursos são adicionados ao cluster Kubernetes, como por exemplo recursos de Nodes da infraestrutura Cloud onde o Scheduler possa endereçar Pods.
Node
Node ou Worker (como chamamos até agora), são os hosts responsáveis por receber toda a carga de trabalho das aplicações de usuário, estes hosts compartilham os recursos de CPU, memória, rede e disco para execução dos Pods.
Para que as aplicações de usuário possam existir no cluster, alguns componentes, que são exclusivos dos Workers, precisam estar em execução. Vamos entender alguns deles agora.
Kubelet

O kubelet é o componente responsável por gerenciar tudo o que está em execução no Worker. Para começar, seu principal papel é registrar o Worker no cluster, para isso ele cria um resource do tipo Node e envia para o API Server.
Outro papel do Kubelet, e não menos importante, é o de monitoramento. O kubelet é responsável por reportar a saúde do Worker e dos Pods em execução, essa tarefa ajuda o Scheduler a ter as informações necessárias para endereçar os Pods aos Worker que estão sempre em bom estado no cluster. Também é função do kubelet iniciar, gerenciar e terminar os containers quando o Pod é deletado.
Todas essas tarefas exigem que o kubelet mantenha comunicação constante com o CRI e o API Server para que as coisas estejam sempre em ordem no cluster.
Container
Até agora vimos os componentes do Kubernetes e já sabemos que o Scheduler endereça o Pod para o Worker e o Kubelet inicia os containers do Pod. Mas até agora não vimos quem é o responsável por criar os containers. Até agora!
Embora possa parecer que o Kubernetes crie os containers não é bem assim que as coisas funcionam, o Kubernetes apenas gerencia o estado dos containers. Para que os containers possam existir é necessário ter acesso ao Kernel do sistema operacional para que os recursos necessário possam ser alocados, e apenas um componente tem acesso a esse nível, o Container Runtime Interface (CRI).
Para gerenciar os containers o Kubernetes apenas faz requisições a API do CRI, este é um dos motivos do Kubernetes ser considerado um Orquestrador de Containers, pois ele pode se comunicar com APIs de diversos CRI.
Proxy

O Kubernetes é um cluster que precisa gerenciar o acesso a diferentes segmentos de rede, como por exemplo a rede externa ao cluster (WAN/internet), a rede local do host do cluster (LAN) e a rede de Pods, conhecida como rede inter-pod.
--pod-networkcidr=172.20.0.0/16
Para que os Pods possam se comunicar sem ter que se preocupar com endereçamento de IP, NAT e roteamento entre os diversos Workers do cluster é necessário usar uma camada de rede que faça esse trabalho, neste caso um componente.
O componente kube-proxy é o responsável por filtrar e encaminhar os pacotes rede de entrada e saída do cluster, este componente deve ser executado em todos os Workers.
Basicamente o kube-proxy utiliza dois métodos para filtrar e encaminhar os pacotes, o mais confiável e de melhor performance é com o uso dos filtros de pacotes do próprio sistema operacional, o mais comum é o iptables. Quando o sistema operacional não oferece uma camada de filtragem de pacotes então o próprio kube-proxy atua encaminhar os pacotes, porém esta configuração não é recomendada para ambientes com grande tráfego devido a perda de performance de rede.
Quando uma aplicação de usuário é distribuída entre diferentes Pods o proxy tem a tarefa de fazer o balanceamento de carga da rede entre todos os Pods da aplicação, mesmo que estejam em Workers diferentes. No próximo artigo veremos mais sobre isso.
Addons
Addons são funcionalidades que não fazem parte do "core" do Kubernetes como os controllers que vimos anteriormente, mas são funcionalidades que podem ser adicionadas ao Kubernetes para oferecer novos recursos ao cluster. Existem uma infinidade de Addons no mercado, vou citar alguns dos quais usamos no nosso cluster Lab.
- Gerenciamento WebGUI: Kubernetes Web UI Dashboard.
- DNS: CoreDNS.
- Gerenciamento, segurança e políticas de rede: Calico e Istio.
- Monitoramento e métrica: ELK, Prometheus, Grafana e Jaeger.
Chegamos ao fim, confesso que quando comecei a escrever este artigo eu tinha em mente os tópicos que poderia passar, o que eu não imaginei é que iria conseguir tirar tanto conteúdo. Eu sei que este post ficou quase o capítulo de um livro (passei muitas horas aqui), mas pode acreditar, tentei trazer um resumo do conteúdo que acho mais interessante sobre a arquitetura do Kubernetes para as pessoas que estão iniciando e querendo aprender um pouco mais sobre Kubernetes. Este artigo está bem de longe de ser tudo o que você precisa saber, muito menos tudo que envolve a arquitetura Kubernetes. Mas acho que já é um bom começo.
Espero que este artigo possa ser muito útil, eu realmente curti as horas que passei aqui escrevendo. Se você gostou, achou algum erro, ou qualquer coisa, escreva um comentário, coloque suas sugestões ou críticas.
E por último, se você está realmente interessado em aprender mais sobre Kubernetes, fique de olho por aqui porque em breve publicarei a terceira parte desta série que será focado nos recursos do Kubernetes, se você é da turma que gosta de mão na massa, o próximo artigo é para você!


Comentários
Postar um comentário